Over the last several parts of this article series, I have talked a lot about the inner workings of the Active Directory. In this article, I want to switch gears and show you what all of this information has to do with running a network.
Windows Server 2003 comes with several different tools used for managing the Active Directory. The Active Directory management tool that you will use most often for day-to-day management tasks is the Active Directory Users and Computers console. As the name implies, this console is used to create, manage, and delete user and computer accounts.
You can access this console by clicking your server’s Start button and navigating through the Start menu to All Programs / Administrative Tools. The Active Directory Users and Computers option should be near the top of the Administrative Tools menu. Keep in mind that only domain controllers contain this option, so if you do not see the Active Directory Users and Computers command, make sure that you are logged into a domain controller.
Another thing that you might notice is that the Administrative Tools menu contains a couple of other Active Directory tools: Active Directory Domains and Trusts and Active Directory Sites and Services. I will be discussing these utilities in future articles.
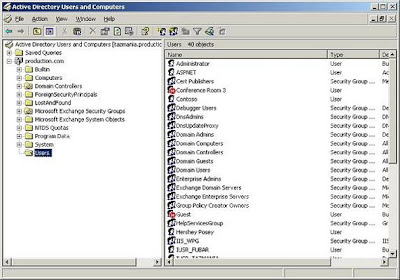
When you open the Active Directory Users and Computers container, you will see a screen similar to the one that is shown in Figure A. As you might recall from previous articles in the series, the Active Directory is based on a forest, which contains one or more domains. Although the forest represents the entire Active Directory, the Active Directory Users and Computers console does not allow you to work with the Active Directory at the forest level. The Active Directory Users and Computers console is strictly a domain level tool. In fact, if you look at Figure A, you will notice that production.com is highlighted. Production.com is a domain on my network. All of the containers listed beneath the domain contain Active Directory objects that are specific to the domain.

Figure A: The Active Directory Users and Computers console allows you to manage individual domains
You might have noticed that I said that production.com was one of the domains on my network, and yet none of my other domains are listed in Figure A. The Active Directory Users and Computers console only lists one domain at a time for the sake of keeping the console uncluttered. Remember when I said that the Active Directory Users and Computers console is only accessible from the Administrative Tools menu if you are logged into a domain controller? Well, the domain that is listed in the console corresponds to the domain controller that you are logged into. For example, in writing this article I logged in to one of the domain controllers for the production.com domain, so the Active Directory Users and Computers console connects to the production.com domain.
The problem with this is that domains are often geographically dispersed. For example, it is fairly common for large companies to have a different domain for each corporate office. If for instance you were in Miami, Florida and the company’s other domain represented an office in Las Vegas, Nevada it would not be practical to have to travel across the country every time you needed to manage the Las Vegas domain. Fortunately, you do not have to.
Although the Active Directory Users and Computers console defaults to displaying the domain that is associated with the domain controller that you are logged in to, you can use the console to display any domain that you have rights to. All you have to do is to right click on the domain that is being displayed and then select the Connect to Domain command from the resulting shortcut menu. Doing so displays a screen that allows you to either type in the name of the domain that you want to connect to, or to click a Browse button and browse for the domain.
Just as a domain might be located far away, you might also find it impractical to log directly in to a domain controller. For example I have worked in several offices in which domain controllers were located in a separate building or too far across the facility that I was in to make logging in to a domain controller impractical for day to day maintenance.
The good news is that you do not have to be logged in to a domain controller to access the Active Directory Users and Computers console. You only have to be logged in to a domain controller to access the Active Directory Users and Computers console from the Administrative Tools menu. You can access the Active Directory Users and Computers console from a member server by manually loading it into the Microsoft Management Console.
To do so, enter the MMC command at the server’s Run prompt. When you do that, the server will open an empty Microsoft Management Console. Next, select the Add / Remove Snap-In command from the console’s File menu. Windows will now open the Add / Remove Snap-In properties sheet. Click the Add button found on the properties sheet’s Standalone tab and you will see a list of all of the available snap-ins. Select the Active Directory Users and Computers option from the list of snap-ins and click the Add button, followed by the Close and OK buttons. The console will now be loaded.
In some situations loading the console in this way may produce an error. If you receive an error and the console does not allow you to manage the domain then right click on the Active Directory Users and Computers container and select the Connect to Domain Controller command from the resulting shortcut menu. This will give you the chance to connect the console to a specific domain controller without actually having to log in to that domain controller. Doing so will allow you to manage the domain as if you were sitting at the domain controller’s console.
That technique works great if you have a server at your disposal, but what happens if your workstation is running Windows Vista, and all of the servers are on the other side of the building?
One of the easiest solutions to this problem is to establish an RDP session with one of your servers. RDP is the Remote Desktop Protocol. It allows you to remotely control servers in your organization. In a Windows Server 2003 environment, you can enable a remote session by right clicking on My Computer and selecting the Properties command from the resulting shortcut menu. Upon doing so, you will see the System Properties sheet. Now, go to the Remote tab and select the Enable Remote Desktop on this Computer check box, as shown in Figure B.

Figure B: You can configure a server to support Remote Desktop connections
To connect to the server from Windows Vista, select the Remote Desktop Connection command from the All Programs / Accessories menu. When you do, you will see a screen similar to the one that is shown in Figure C. Now, just enter the name of your server and click the Connect button to establish a remote control session.

Figure C: Windows Vista makes it easy to connect to a remote server
In this article, I have begun demonstrating the Active Directory Users and Computers console. I have also explained how you can use this console to manage remote domains. In Part 12 I will continue the discussion by showing you more of the Active Directory Users and Computers console’s capibilities.